밑바닥부터 시작하는 딥러닝 4단원 - 신경망 학습
p 108 - 146
학습이란?
훈련 데이터로부터 가중치 매개변수의 최적값을 자동으로 획득하는 것
신경망이 학습할 수 있도록 해주는 지표 → 손실함수
목표 : 손실 함수의 결과값을 가장 작게 만드는 가중치 매개변수를 찾는 것 !
<경사법>
손실 함수의 값을 가급적 작게 만드는 기법으로 함수의 기울기를 활용함
신경망의 특징은 데이터를 보고 학습할 수 있다는 점이다.
= 가중치 매개변수의 값을 데이터를 보고 자동으로 결정한다
1. 데이터 주도 학습
기계학습은 데이터가 생명이다 !
어떤 문제를 해결하려고 할 때, 패턴을 찾아내야 할 때
사람의 경험과 직관을 단서로 시행착오를 거듭하며 일을 진행한다.
반면 기계학습에서는 사람의 개입을 최소화하고
수집한 데이터로부터 패턴을 찾으려 시도한다.

'5'를 인식하는 알고리즘을 설계하는 것은 어려움 ..
대신
이미지에서 특징(feature)을 추출하고
그 특징의 패턴을 기계학습 기술로 학습하는 방법이 있음!
여기서 말하는 특징 :
입력 데이터 (입력 이미지)에서 본질적인 데이터(중요한 데이터)를
정확하게 추출할 수 있도록 설계된 변환기를 가리킴
이미지의 특징은 보통 벡터로 기술
컴퓨터 비전 분야에서는 SIFT, SURF, HOG 등의 특징 사용
-> 이미지 데이터를 벡터로 변환, 변환된 벡터를 가지고
지도 학습의 방식( SVM, KNN 등 )으로 학습
다만 이미지를 벡터로 변환할 때 사용하는 특징은 여전히 '사람'이 설계한다 !
(문제에 적합한 특징을 써야함)

두 번째 접근 방식(특징과 기계학습 방식)에서는 특징을 사람이 설계했지만,
신경망은 이미지에 포함된 중요한 특징까지도 '기계'가 스스로 학습함
신경망의 이점은 모든 문제를 같은 맥락에서 풀 수 있다는 것
' end-to-end ' 로 학습 가능
훈련 데이터 & 시험 데이터
훈련 데이터만 사용하여 학습하며 최적의 매개변수를 찾는다
시험 데이터를 사용하여 훈련한 모델의 실력을 평가한다
훈련 & 시험 데이터를 나누는 이유? 모델의 범용 능력을 제대로 평가하기 위해서!
** 한 데이터셋에만 지나치게 최적화된 상태: 오버피팅
2. 손실함수
신경망은 하나의 지표를 기준으로 최적의 매개변수 값을 탐색한다.
신경망 학습에서 사용하는 지표: 손실 함수 (loss function)
이 손실함수는 일반적으로 오차제곱합과 교차 엔트로피 오차를 사용한다
손실 함수는 신경망 성능의 '나쁨'을 나타내는 지표
현재의 신경망이 훈련 데이터를 얼마나 잘 처리하지 못하는지
1) 오차제곱합 sum of squares of error, SSE
가장 많이 쓰이는 손실 함수

y_k : 신경망의 출력 (신경망이 추정한 값)
t_k : 정답 레이블 → (원-핫 인코딩)
k는 데이터의 차원 수
2) 교차 엔트로피 오차 cross entropy error, CEE

log: 자연로그
CEE 는 실질적으로 정답일 때의 추정 ( t_k 가 1일 때의 y_k)의 자연로그를 계산하는 식
▶ 교차 엔트로피 오차는 정답일 때의 출력이 전체 값을 정함

CEE 값: 정답에 해당하는 출력이 커질수록 0에 다가가고, 그 출력이 1일 때 0이 된다
3. 수치 미분
왜 '정확도'라는 지표 대신 '손실 함수의 값'이라는 우회적인 방법을 택할까?
신경망 학습에서의 미분의 역할에 주목하면 해결된다
정확도를 지표로 하면 매개변수의 미분이 대부분의 장소에서 0이 되기 때문이다.
경사법에서는 기울기(경사) 값을 기준으로 나아갈 방향을 정한다.
1) 미분
좌변: f(x)의 x에 대한 미분 ( x에 대한 f(x)의 변화량)

문제점 : 수치 미분에는 오차가 포함된다.

2) 편미분
변수가 여럿인 함수에 대한 미분


편미분은 변수가 하나인 미분과 마찬가지로 특정 장소의 기울기를 구한다.
단 여러 변수 중 목표 변수 하나에 초점을 맞추고 다른 변수는 값을 고정한다.
기울기
- 경사 하강법 (경사법)
- 신경망에서의 기울기
모든 변수의 편미분을 벡터로 정리한 것을 기울기(gradient) 라고 한다.
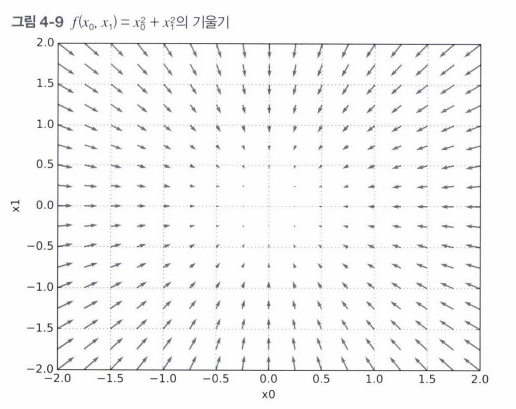
기울기가 가리키는 쪽은 각 장소에서 함수의 출력 값을 가장 크게 줄이는 방향 !
1) 경사법 (경사 하강법)
일반적인 문제의 손실 함수는 매우 복잡하다.
매개변수 공간이 광대하여 어디가 최솟값인지 찾기 어려움
학습 알고리즘 구현하기
- 2층 신경망 클래스 구현하기
'[Deep Learning] 딥러닝 기초' 카테고리의 다른 글
| DL 스터디 - 다차원 배열 & Softmax function (0) | 2024.01.16 |
|---|---|
| DL 스터디 - 신경망 & 활성화 함수 (0) | 2024.01.16 |
| DL 스터디 - 퍼셉트론 (2) | 2024.01.09 |